tair使用规范
Untitled
[toc]
文件间跳转
数学表达式
要启用这个功能,首先到Preference->Editor中启用。然后使用$符号包裹Tex命令,例如:$lim_{x \to \infty} \ exp(-x)=0$将产生如下的数学表达式:
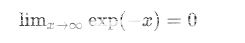
下标
下标使用~包裹,例如:H~2~O将产生水的分子式。
上标
上标使用^包裹,例如:y^2^=4将产生表达式

插入表情
使用:happy:输入高兴的表情,使用:sad:输入悲伤的表情,使用:cry:输入哭的表情等。以此类推!

下划线
用HTML的语法Underline将产生下划线Underline.
删除线
GFM添加了删除文本的语法,这是标准的Markdown语法木有的。使用~~包裹的文本将会具有删除的样式,例如~删除文本~将产生删除文本的样式。
代码
使用`包裹的内容将会以代码样式显示,例如
使用printf()
则会产生printf()样式。
输入~~~或者```然后回车,可以输入代码块,并且可以选择代码的语言。例如:public Class HelloWorld{ System.out.println(“Hello World!”); }
强调
使用两个*号或者两个_包裹的内容将会被强调。例如
使用两个*号强调内容 使用两个下划线强调内容
将会输出
使用两个号强调内容 使用两个下划线强调内容 Typroa 推荐使用两个号。
斜体
在标准的Markdown语法中,*和_包裹的内容会是斜体显示,但是GFM下划线一般用来分隔人名和代码变量名,因此我们推荐是用星号来包裹斜体内容。如果要显示星号,则使用转义:
*
插入图片
我们可以通过拖拉的方式,将本地文件夹中的图片或者网络上的图片插入。
插入URL连接
使用尖括号包裹的url将产生一个连接,例如:将产生连接:www.baidu.com.
如果是标准的url,则会自动产生连接,例如:www.baidu.com
目录列表Table of Contents(TOC)
输入[toc]然后回车,将会产生一个目录,这个目录抽取了文章的所有标题,自动更新内容。
水平分割线
使用***或者—,然后回车,来产生水平分割线。
标注
我们可以对某一个词语进行标注。例如
某些人用过了才知道[^注释] [^注释]:Somebody that I used to know.
将产生:
把鼠标放在注释上,将会有提示内容。
特殊语法
MYSQL中的COLLATE是什么?
指定排序规则
Untitled
问题汇总
1. 时间类型字段问题
1.1 时区问题
现象一:写入时间在mysql中查看,与实际时间相差几个小时,程序读出来又是正常的
MySQL数据时区问题,及datetime和timestamp类型存储的差异
MySQL Config–参数system_time_zone和参数time_zone
查询系统分区:
1 | show global variables like'%time_zone%' |
解决方案:
1 | jdbc:mysql://10.48.204.231:5002/waimai_hubble_analysis_test?useUnicode=true&useSSL=false&serverTimezone=GMT%2B8 |
命令
[toc]
find
grep
awk
curl
如果有特殊字符,导致解析失败
-
用单引号引起来,这样会原封不动的使用,而不会尝试去解析
1
curl -k -v -X POST "https://xxx.net/livy/batches" -u 'admin:xxx!QAZ' -H "Content-Type: application/json" -H "X-Requested-By: admin" -d '{"file":"/users/jingqicao/sparkSubmission/SAMStreaming/ver-01/bin/SAM-1.0-SNAPSHOT.jar", "driverMemory": "30G", "driverCores": 4, "executorCores": 14, "executorMemory": "98G", "numExecutors": 256, "name": "SAMStreaming-ver01-1020-02", "className":"com.microsoft.sam.SAMJobRunner", "args":["ver-01-1020-02","/users/jingqicao/sparkSubmission/SAMStreaming/ver-01/bin/SAMJob_4HD.conf"]}'
nautilus
ps
查看当前进程
1 | ps aux |
查看进程父子关系
1 | 1. |
Untitled
基础
确认
使用的shell类型
1 | echo $SHELL |
| 类型 | 登陆时读取的配置文件 | 未登录时读取的配置文件 |
|---|---|---|
| Zsh | ~/.zprofile或~/.zlogin |
~/.zshrc |
| Bash | ~/.bash_profile、~/.bash_login、~/.profile(按顺序查找第一个) |
~/.bashrc |
命令
查看系统信息
架构
1 | uname -a |